DerLex: an eye-tracking database of derived word reading
 DerLex: a large eye-tracking database of derived (suffix) word reading in English.
DerLex: a large eye-tracking database of derived (suffix) word reading in English.The big idea
A lot of theories about morphological processing are tested with small experiments that can miss subtle effects. DerLex is a large, shared dataset that lets researchers study how people read derived words in sentences using eye tracking—at a scale that supports stronger, more reliable conclusions.
Importantly, DerLex is built to “talk to” CompLex, our companion megastudy of compound word reading: the derived-word stimuli were collected in the same general wave of data collection and the identifiers are designed so the two datasets can be merged for broader questions about morphological complexity.
What we did
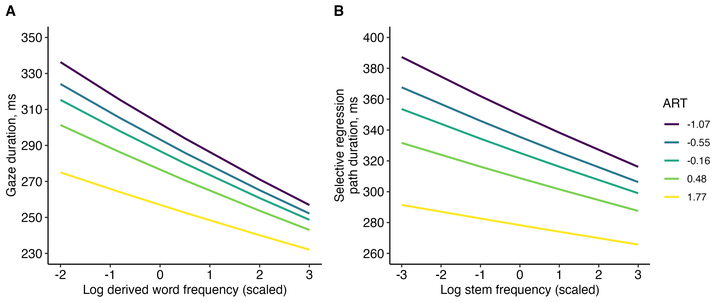
- Built a sentence-reading eye-tracking database with 598 unique derived suffixed words read by 357 participants.
- Structured the resource to mirror CompLex (methods + goals), so researchers can compare derived-word effects with compound-word effects in a consistent framework.
- Provided practical power/sample-size estimates to help researchers plan well-powered eye-tracking studies of morphology.
What we found
- Some benchmark effects are robust and show up clearly, but many theoretically interesting effects are surprisingly hard to detect—even in an overpowered dataset—highlighting where the field may need better designs or stronger manipulations.
Why it matters
DerLex is meant to be a community resource: it supports transparent, well-powered tests of morphological theory, and—together with CompLex—it makes it easier to ask bigger questions about how readers process different kinds of complex words in natural sentence reading.
Daniel Schmidtke
Research Associate
My research interests include psycholinguistics, corpus linguistics and linguistic theory.